|
||||

What is the context ?Near the end of 1990's, the concept of These frameworks can be compared with ERP's although their respective domains of application are different : their ambition is to manage the whole information system through an integrated unique offer. Since several months, many study groups like Gartner Group or Meta Groups grants to make a mitigated balance on the usage of these frameworks. The complexity of implementation of these platforms seems to have made indeed fail close to 3 projects on 4. Besides, the very elevated costs of licenses and deployment have limited such a solution perimeter to big companies. Historically, the principles of network supervision are older than those governing the frameworks and mainly based upon the SNMP protocol (and its extensions). Numerous network monitoring offers are today available on the market. That's why the editors leaders of the sector, conscious of the competitive hazard that the frameworks represent, made their offer to evolve toward system and applications monitoring. However, network supervision platforms do not constitute the ideal basis for systems and application supervision. Therefore, most users are today facing a spiny problem : there is no available pragmatic approach for the global network, systems and applications supervision and, with the international dimension of today's projects, this supervision of distributed systems is becoming necessary and primordial and it requires a wide panel of services :
These services requirements lead to have a set of independent software components designed in a distributed way using the following technologies :
What is the current situation ?Today, the performance of information systems directly governs company competitiveness, such is the report that can be pulled from the evolution of the information technologies. The supervision of the computer
infrastructure becomes therefore an element of vital importance for the whole set of
companies. In a context where So, a convergence of the different supervision offers has been observed toward a "single vision" consisting in an enterprise type approach. This new tendency is related to the will of, on one hand, the "systems supervision" solutions editors to open their products to the network and, on the other hand, the "network supervision" developers to integrate in their solutions a system monitoring. But today, none of these available solutions was specifically designed to fulfil its principal task: the global supervision with an "enterprise" point of view. Historically, these solutions are mainly proprietary, most of the time made of a pool of offers acquired by the mean of external growth and aimed at covering a large functional scale. Today, the supervision of distributed systems is mainly done on a case by case basis and also mainly at independent technical services levels. The distributed applications used on these systems are supervised in a very limited way. Furthermore, the user-interface is often questionable as it requires expert people and suffers from a lack of automation and user friendliness.
What is the GeneSyS added-value ?An important innovation of the GeneSyS concept is to adopt a universal approach for the supervision of distributed systems. This design approach can be structured in three main axis :
Then the GeneSyS project will conduct two major evolutions in the field of distributed systems supervision :
The GeneSyS middlewareThe purpose of the GeneSyS middleware is to improve the communication infrastructure by introducing several new concepts :
The generic aspect of the GeneSyS middleware will be ensured by basing the communication infrastructure on IP level in order to be independent of the network technology. The open source initiative will offer several benefits compared to standard commercial products which are mainly proprietary :
Most of existing middleware available on the market are using the service of a central repository where resides all the information about the nodes available on the network :
This situation makes non appropriate the use of these products for distributed systems supervision and confirms the interest for the GeneSyS solution : GeneSyS middleware will provide simple "point to point" and "publish and subscribe" mechanism without the need of a global repository. This will guarantee maximum simplicity and efficiency for exchanging information between any client applications.
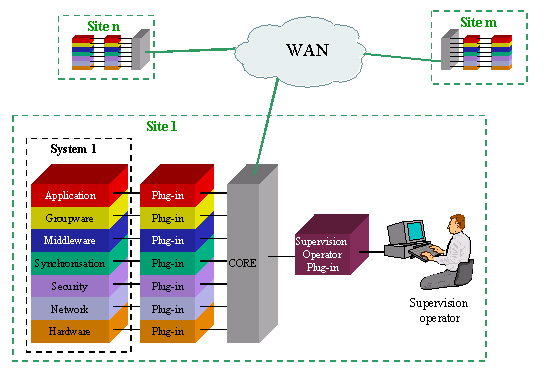
The GeneSyS standard interfacesThe architecture of the GeneSyS system requires the definition of interfaces at different levels. First there is an instrumentation level that enables a hardware device or software system to be integrated into the GeneSyS monitoring middleware. So for each device that will be monitored with GeneSyS, a set of standard functionalities (e.g. lifecycle functionalities such as join, leave or authentication) has to be implemented. A starting point for defining the basic functionality could be the functionality found in JINI and peer-to-peer frameworks such as JXTA (http://www.jxta.org) Beside this basic functionality type, specific extensions that reflects extended functionality of a device has to be provided. The GeneSyS project will define the API for the basic functionality of Plug-Ins and also the extended functionality expected from specific devices such as hardware, network, middleware and all other identified layers. In order to keep the API for the plug-ins as simple as possible, the specific functionality could be provided by the plug-ins for example through a description e.g. as XML document as used for the WSDL (Web Service Description Language) in the context of Web-Services. As plug-ins are supposed to be implemented for very different devices and therefore in different programming languages, the API should be language neutral. Beside this API that covers the connection of devices to the middleware, an API to the standard services of the GeneSyS middleware ("Core") has to be provided in order to allow the implementation of custom client applications that exploit the functionalities of the Core. The applications can be used for monitoring or controlling the devices connected to the GeneSyS architecture.
The GeneSyS architectureThe previous concepts, when implemented on a prototype, will lead to an open, generic, modular and comprehensive framework for system and application supervision. To ensure the openness and generic aspect of the supervision, the GeneSyS architecture is based on two distinct types of entities:
The GeneSyS Core will have :
The Plug-ins implement these functions :
A Plug-in will be able to control and monitor several services upon several hardware and software components (such as network equipment, workstations or applications). The GeneSyS architecture will be based as far as possible on a number of existing standards in middleware technology, such as CORBA (Common Object Request Broker Architecture) and HLA (High Level Architecture - IEEE 1516), as well as on well-established network protocols such as SNMP (Simple Network Management Protocol), ICMP (Internet Control Message Protocol), Ipv4 and IPv6 (Internet Protocol version 4&6), DiffServ (Differentiated Services) and NTP (Network Time Protocol). The use of these standards and protocols will contribute to the open and generic aspects of the solution.
|